Streaming JSON from OpenAI API
Introduction
This blog posts explains how streaming from the OpenAI API improves user experience (UX). More importantly, we look how you can stream JSON data. We provide examples using Next.js, Vercel AI SDK and my very own http-streaming-request library.
Why do you need streaming?
Have you ever used an Open AI API in your code? If so, you may have noticed that it can take up to 10 seconds for the API to respond. So you may have to display a spinning wheel (of doom) to users. That's not great user experience - people may think your app is broken and leave.

On the other hand, ChatGPT doesn't make you wait - it starts printing out a response almost immediatelly - character by character (well, token by token).
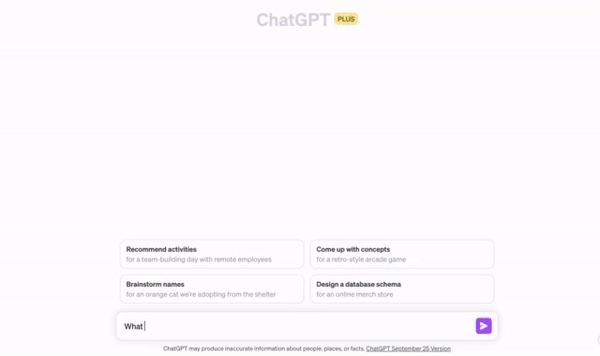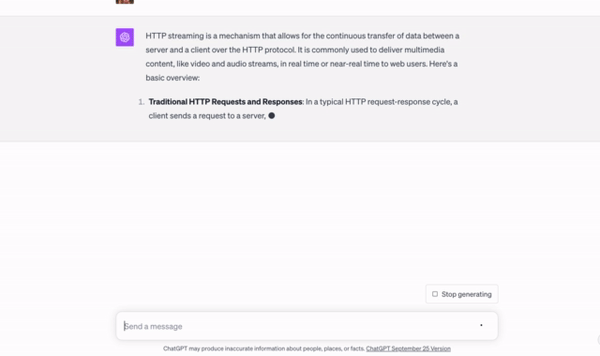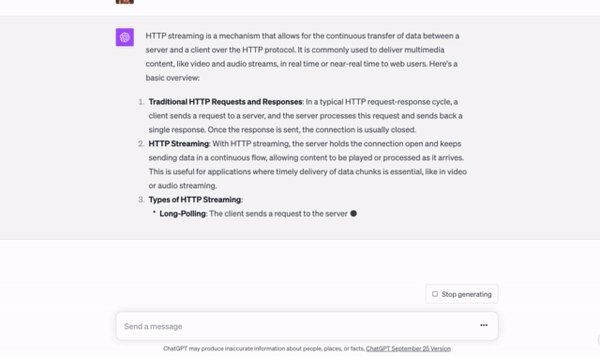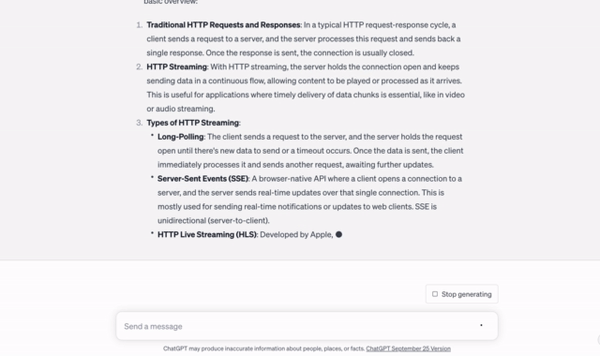
So what ChatGPT does is not just a gimmick, which makes it look like a retro sci-fi film, but a very useful UX technique. It lets users get partial results almost straight away.
Yes, it still takes the same amount of time to get a full response but:
- You can start reading an answer almost as soon as you've submmited a question
- And you don't get an impression that it is broken or slow
How can you get started with streaming?
Okay, streaming is useful! But how can you get started with streaming?
Actually, it's not that difficult and there are already a number of tutorials on the Internet. For the purpose of this article we use Next.js with the Vercel AI SDK.
Streaming text response
Let's start with a simple example - streaming text. We have a simple prompt that returns text data.
Since we've decided to use Next.js, the API endpoint will look like this:
import OpenAI from "openai";
import { OpenAIStream, StreamingTextResponse } from "ai";
export const runtime = "edge";
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY!,
});
export async function POST(_: Request) {
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
stream: true,
messages: [
{
role: "user",
content: "Key dates in the Italian history.",
},
],
});
const stream = OpenAIStream(response);
return new StreamingTextResponse(stream);
}
And the very basic frontend code will be this:
"use client";
import { useCompletion } from "ai/react";
export default function VercelStreamingText() {
const { complete, completion } = useCompletion({
api: "/api/text-ai",
});
const onRunClick = () => {
complete("");
};
return (
<div className="space-y-3">
<button onClick={onRunClick}>Run</button>
<div>{completion}</div>
</div>
);
}
The main thing in that code is the use of the useCompletion() hook which will call the API (on invoking complete()) and will stream results into the completion variable.

Streaming JSON
Streaming text is is easy. But what if you have to stream JSON? That's where things get more complicated.
But why would you ask an LLM to return JSON in the first place?
Getting JSON is super useful if you need a structured response that you want to parse programatically. For example, this year I and a few other people have built this products where we've instructed the LLM to return JSON:
- PowerMode - the AI powered slide deck generator. The LLM there returns an array of slides. Each slide is an object with the attributes of
title,type: bullet-points | textandcontent. Thecontentattribute is either a string for text only slides or an array of bullet points. Once we start receiving JSON we pass it to the rendering engine on the frontend that turns them into slides on the screen.= - No Echo News - you give it a link to a news article - and it finds you stories that have a different point of view. A call to OpenAI there also returns an array. This time each object is an article with attributes of
title,articleUrland an explanation on why the AI thinks that article provides a different point of view.
Let's try to stream JSON
First of all, let's change the prompt to ask the GPT to return us JSON.
Key dates in Italian history.
Return only a JSON array with no surrounding text.
Each object in the array should have two attributes - date and event.
If we stream that to the browser we'll just get a text represantation of JSON. That's not what we wanted. Instead we want to parse JSON and format it according to our liking.
Well, we can write something like this:
// let's define the expected type
interface HistoricEvent {
date: string;
event: string;
}
// and then do this in the React component:
const [events, setEvents] = useState<HistoricEvent[]>([]);
const { complete, completion } = useCompletion({
api: "/api/json-ai",
});
const onRunClick = () => {
complete("");
};
useEffect(() => {
if (completion.length > 0) {
setEvents(JSON.parse(completion);
}
}, [completion]);
Unfortunately, you'll get an error from JSON.parse() as soon as you hit the 'Run' button.
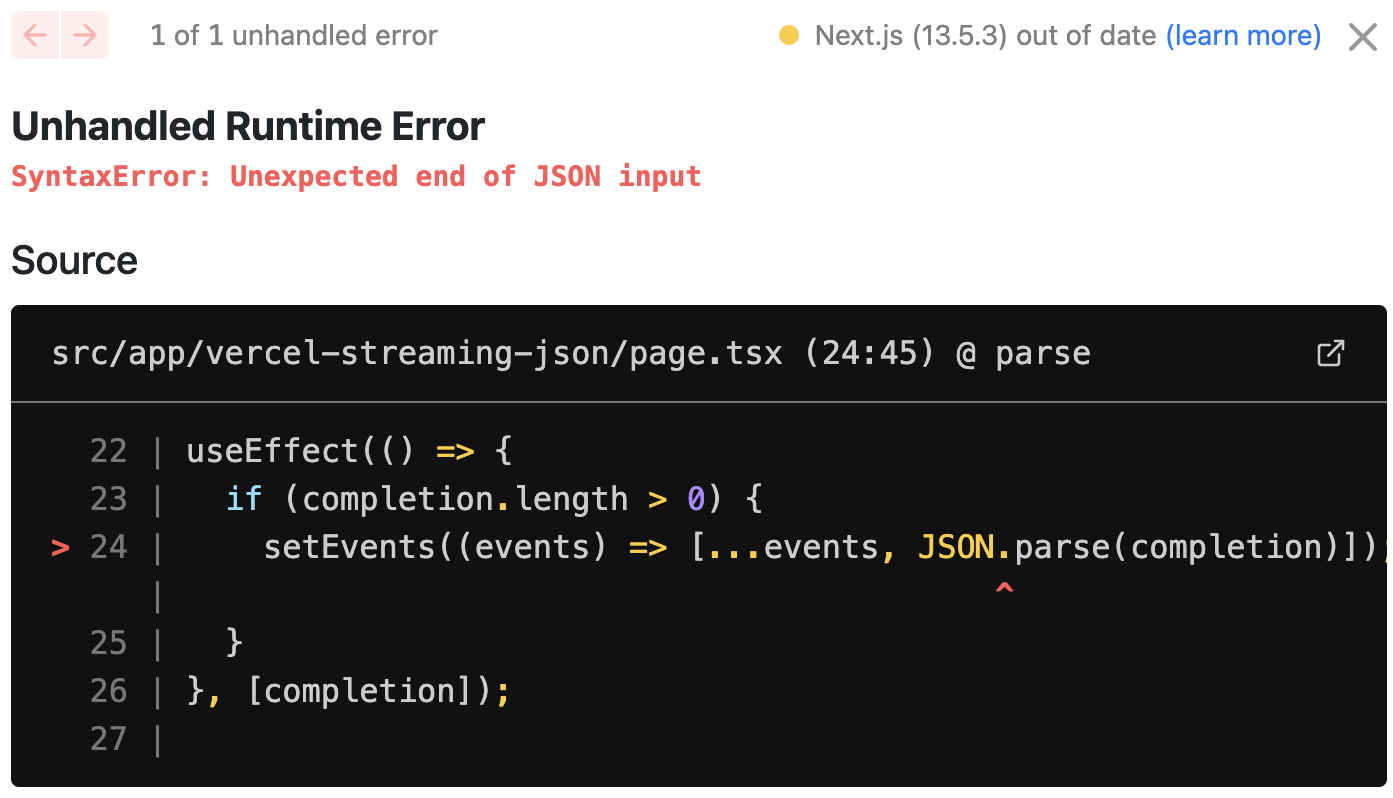
And that totally makes sense - when you stream JSON at almost every single moment you get an invalid JSON that cannot be parsed. For example, the first streaming output could be:
[{"date
And the second one might be:
[{"date": "30AD", "event":
None of that is something that JSON.parse() can process.
Processing JSON optimistically
When getting an output that has incomplete JSON our best option is to process it optimistically, i.e. if the JSON is not complete, let's assume that it is and close all double quotes, curly and square brackets.
Luckily we don't have to do it manually, as there is a great library that does it for us - best-effort-json-parser .
import { parse } from "best-effort-json-parser";
// and then in the React component
useEffect(() => {
if (completion.length > 0) {
setEvents(parse(completion));
}
}, [completion]);
http-streaming-request library
I've also gone a step further and abstracted both the HTTP call and JSON parsing into a library - http-streaming-request, so that you can do it all with a few lines of code.
import { useJsonStreaming } from "http-streaming-request";
// and then in the React component
const { data: people, run } = useJsonStreaming<HistoricEvent[]>({
url: "/api/ai-json",
method: "POST",
manual: true,
});
const onRunClick = () => {
run();
};
And that's it! Also note that it comes with TypeScript generics.
You can see this example in action here
Also this library does not have any dependency on Next.js or the Vercel AI SDK. And it can be used with any backend, provided the API streams a chunked response.
Conclusion
- The LLMs are slow. Don't let the user wait - stream a response straight away
- It's possible to stream JSON, but you have to parse it optimistically.
- There are libraries for optimistic JSON parsing
- And http-streaming-request that abstracts all complexity away
- Also check the Vercel AI SDK
The opinions expressed herein are my own personal opinions and do not represent my employer's view in any way. My personal thoughts tend to change, hence the articles in this blog might not provide an accurate reflection of my present standpoint.
© Mike Borozdin